
商品详情

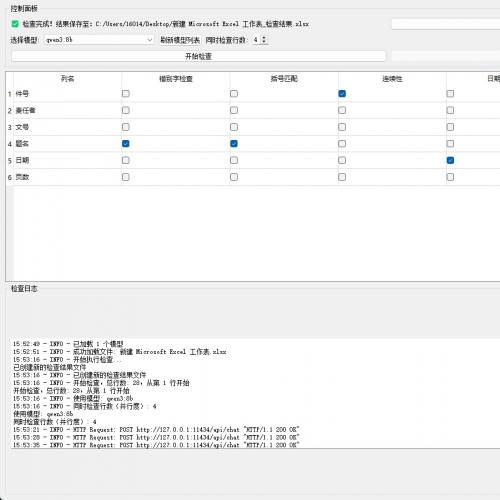





本工具专为档案数字化流程设计,融合前沿大语言模型技术,提供精准的错别字检测功能。
通过引入多线程运行机制,在硬件配置允许的前提下显著提升处理速度,满足大批量文本校验需求。
用户只需将.xlsx格式的Excel文件拖入软件界面,勾选需检测的列项内容,点击“运行”即可启动分析流程。
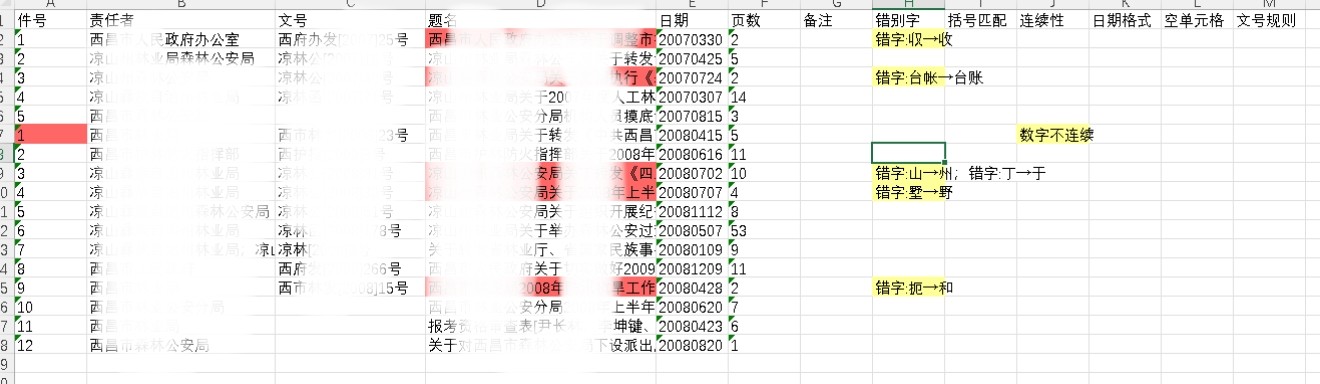
任务完成后,系统将在原始文件所在目录自动生成详细检测报告,方便快速定位和修正错误。
软件支持所有可通过Ollama平台运行的语言模型,包括但不限于DeepSeek、Qwen、GPT系列等。
实测使用qwen3:8b模型表现稳定,效果出色。
用户可根据实际需要自由选择模型进行本地部署。
所有处理均在本地完成,无需上传文件至云端,确保敏感信息不外泄。
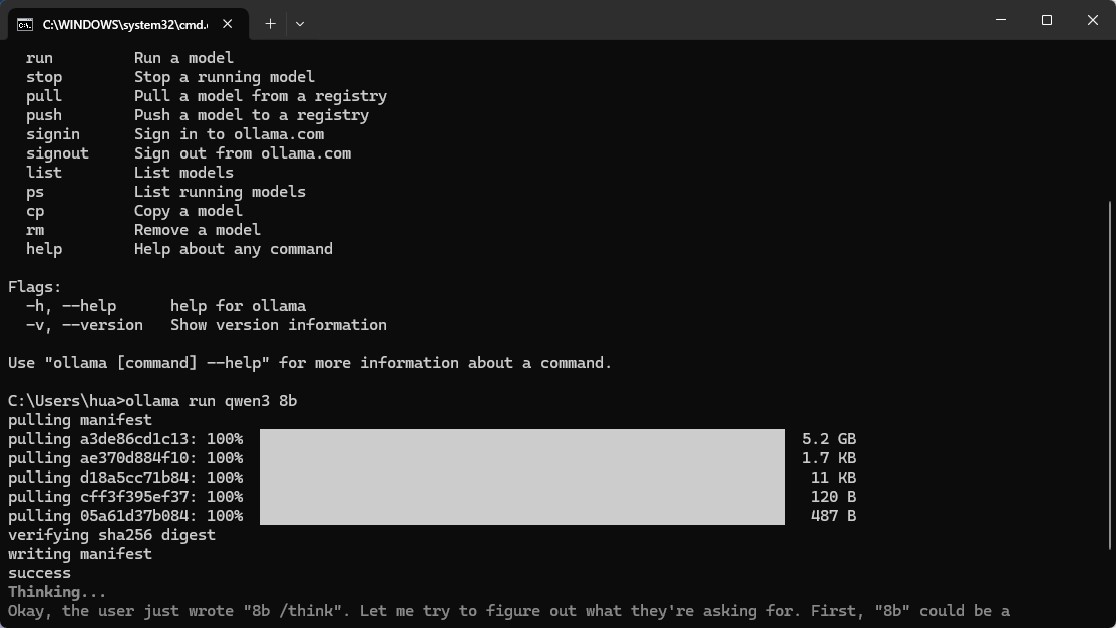
建议提前在本地安装并配置好Ollama环境及所需模型,确认模型可正常对话后再启动本工具,以保证运行稳定性。
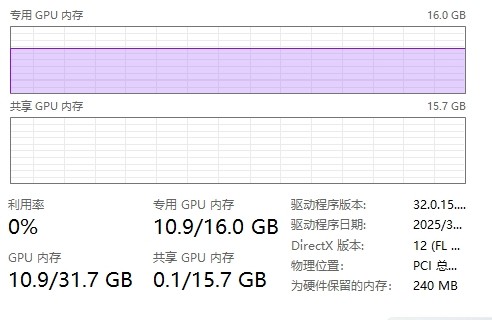
为获得良好体验,建议电脑配备独立显卡。
集成显卡可能导致运行极慢甚至无法加载模型。
测试环境显示,显存10GB以上时可同时处理约5条数据,单条检测耗时约15秒。
显存不低于6GB,推荐8GB及以上,避免出现闪退或性能瓶颈。
首次使用需联网下载对应模型,整合包内含Ollama安装程序及自动化脚本,但必须保持网络连接。
若下载中断或变慢,可关闭命令窗口后重新运行,支持断点续传。
本软件仅支持Windows 10及以上操作系统,暂不兼容Mac或Linux。
文件格式限定为.xlsx,不支持.xls或其他类型。
为虚拟,后不退不换。
开发者非科班出身,与多数用户属同行交流性质,若遇异常情况可能无法提供技术支持。
如有其他档案管理类软件需求,欢迎咨询,部分功能将视情况单独上架发布。


发货方式
自动:在特色服务中标有自动发货的商品,拍下后,源码类 软件类 商品会在订单详情页显示来自卖家的商品下载链接,点卡类 商品会在订单详情直接显示卡号密码。
手动:未标有自动发货的的商品,付款后,商品卖家会收到平台的手机短信、邮件提醒,卖家会尽快为您发货,如卖家长时间未发货,买家也可通过订单上的QQ或电话主动联系卖家。
退款说明
1、源码类:商品详情(含标题)与实际源码不一致的(例:描述PHP实际为ASP、描述的功能实际缺少、功能不能正常使用等)!有演示站时,与实际源码不一致的(但描述中有"不保证完全一样、可能有少许偏差"类似显著公告的除外);
2、营销推广类:未达到卖家描述标准的;
3、点卡软件类:所售点卡软件无法使用的;
3、发货:手动发货商品,在卖家未发货前就申请了退款的;
4、服务:卖家不提供承诺的售后服务的;(双方提前有商定和描述中有显著声明的除外)
5、其他:如商品或服务有质量方面的硬性常规问题的。未符合详情及卖家承诺的。
注:符合上述任一情况的,均支持退款,但卖家予以积极解决问题则除外。交易中的商品,卖家无法修改描述!
注意事项
1、在付款前,双方在QQ上所商定的内容,也是纠纷评判依据(商定与商品描述冲突时,以商定为准);
2、源码商品,同时有网站演示与商品详情图片演示,且网站演示与商品详情图片演示不一致的,默认按商品详情图片演示作为纠纷评判依据(卖家有特别声明或有额外商定的除外);
3、点卡软件商品,默认按商品详情作为纠纷评判依据(特别声明或有商定除外);
4、营销推广商品,默认按商品详情作为纠纷评判依据(特别声明或有商定除外);
5、在有"正当退款原因和依据"的前提下,写有"一旦售出,概不支持退款"等类似的声明,视为无效声明;
6、虽然交易产生纠纷的几率很小,卖家也肯定会给买家最完善的服务!但请买卖双方尽量保留如聊天记录这样的重要信息,以防产生纠纷时便于送码网快速介入处理。
淘好品声明
1、作为第三方中介平台,依据双方交易合同(商品描述、交易前商定的内容)来保障交易的安全及买卖双方的权益;
2、平台上所有的资源都是亲测无误的,在平台下单安全有保障,有任何问题,可以随时联系在线客服。






