
商品详情






本小说推荐系统采用Spark与Hadoop双引擎驱动,充分发挥Hadoop在分布式存储方面的优势,结合Spark高速内存计算能力,实现对海量小说文本和用户行为数据的快速处理与分析。
无论是TB级的数据量还是实时推荐请求,系统均能稳定高效运行,为个性化服务提供坚实基础。
系统内置基于用户的协同过滤(User-Based Collaborative Filtering)算法,通过分析用户阅读历史、评分、点击等行为数据,计算用户之间的相似度,精准预测目标用户可能感兴趣的小说内容。
推荐结果更贴近真实偏好,显著提升用户体验与平台粘性。
项目采用主流技术组合:后端使用Django框架构建RESTful接口,前端基于HTML、CSS与JavaScript实现交互界面,并利用Echarts进行数据可视化展示。
数据处理层由Spark完成清洗、建模与计算,数据存储依托Hive构建数据仓库,形成一套完整的大数据处理流水线。
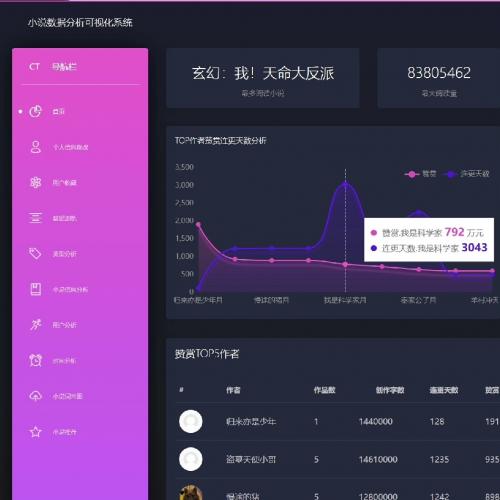
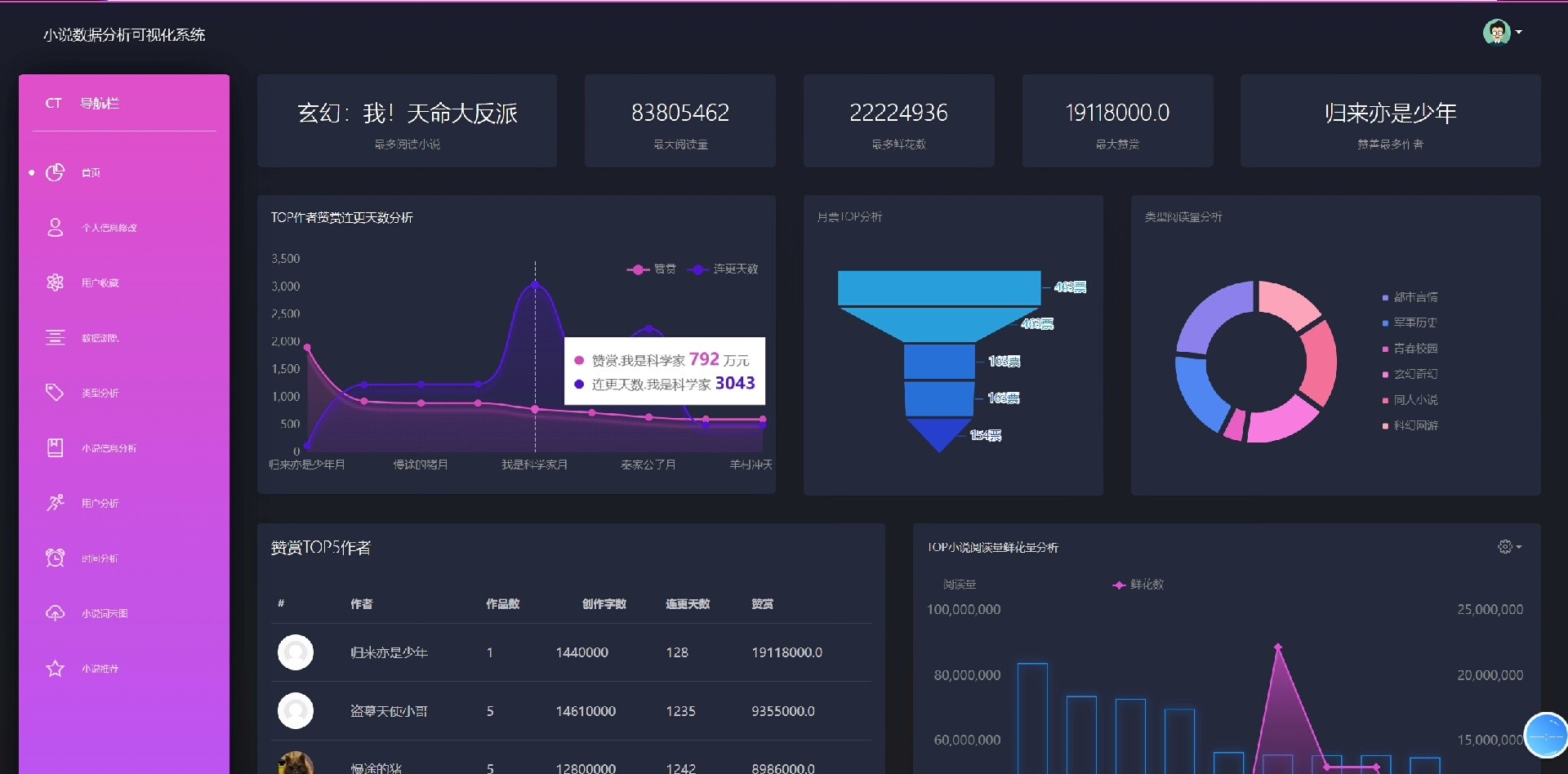
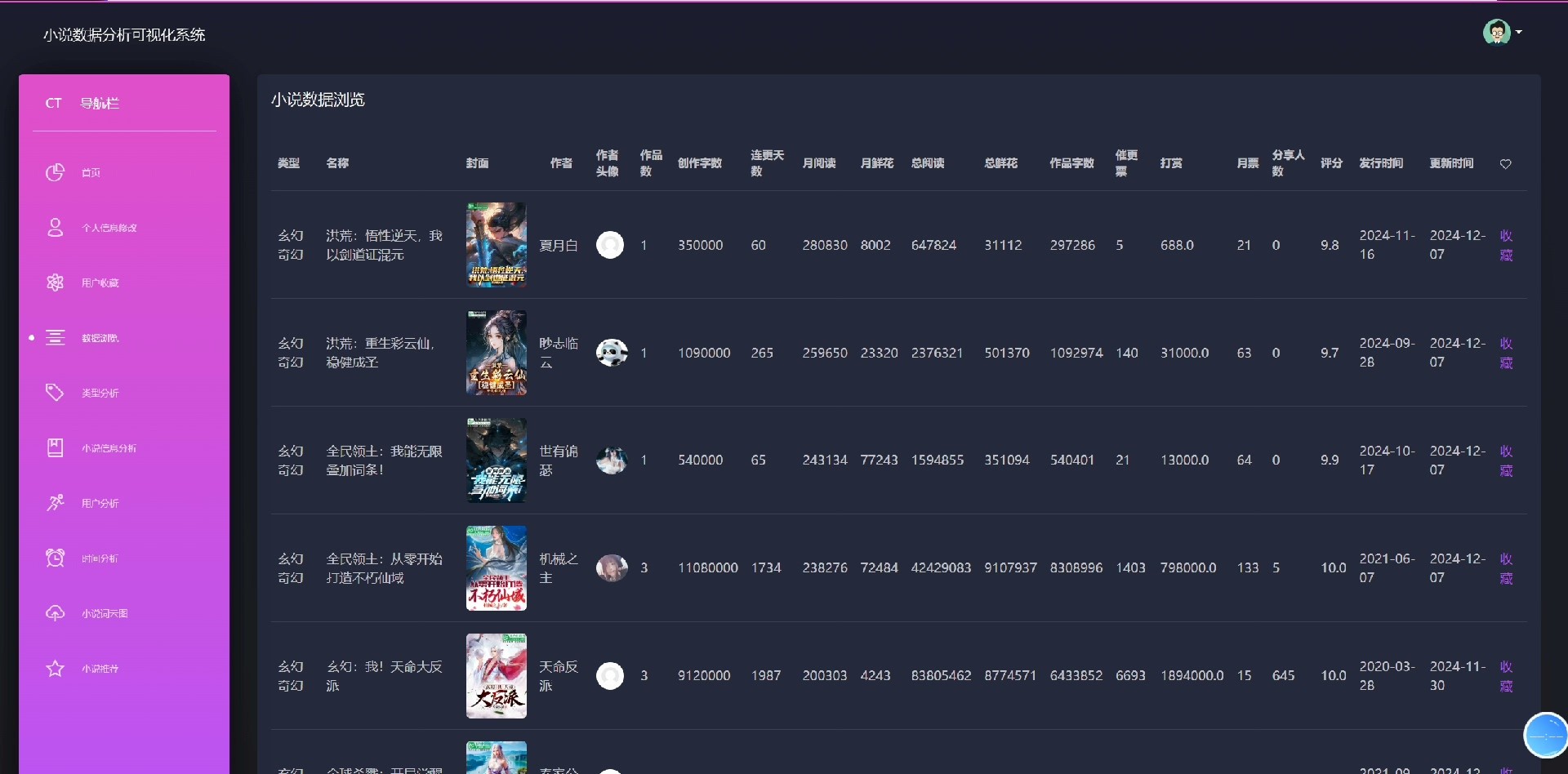
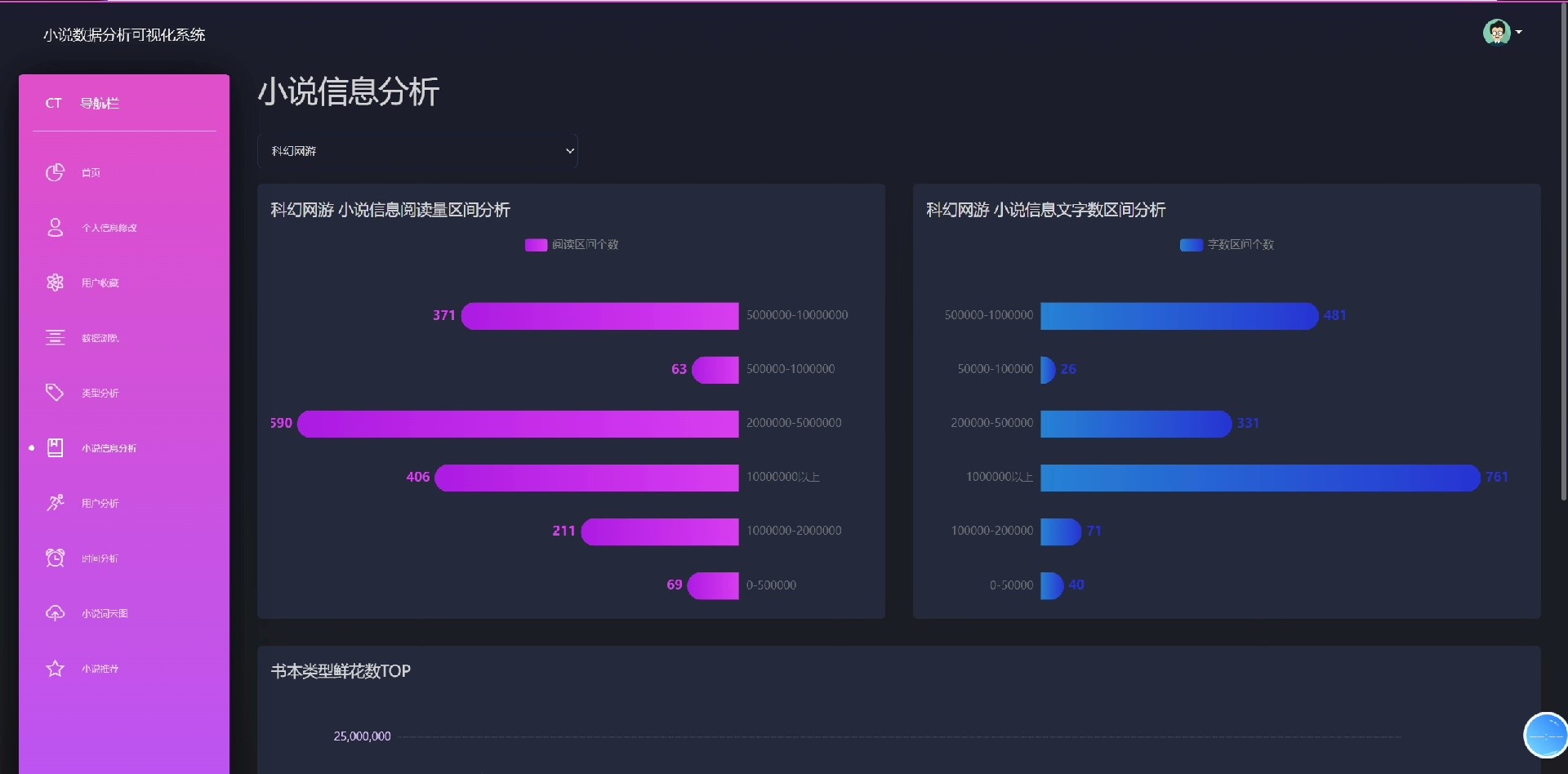
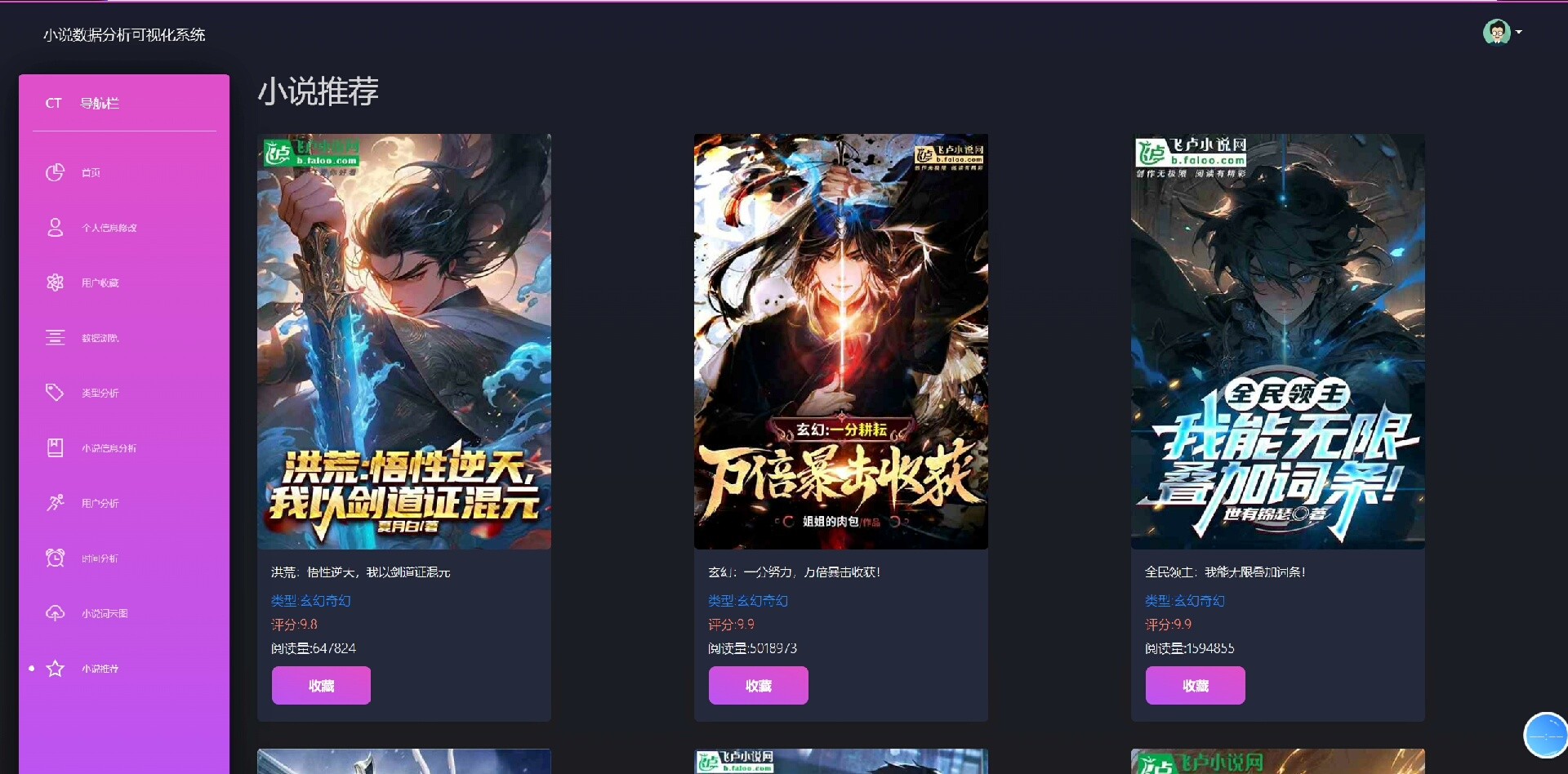
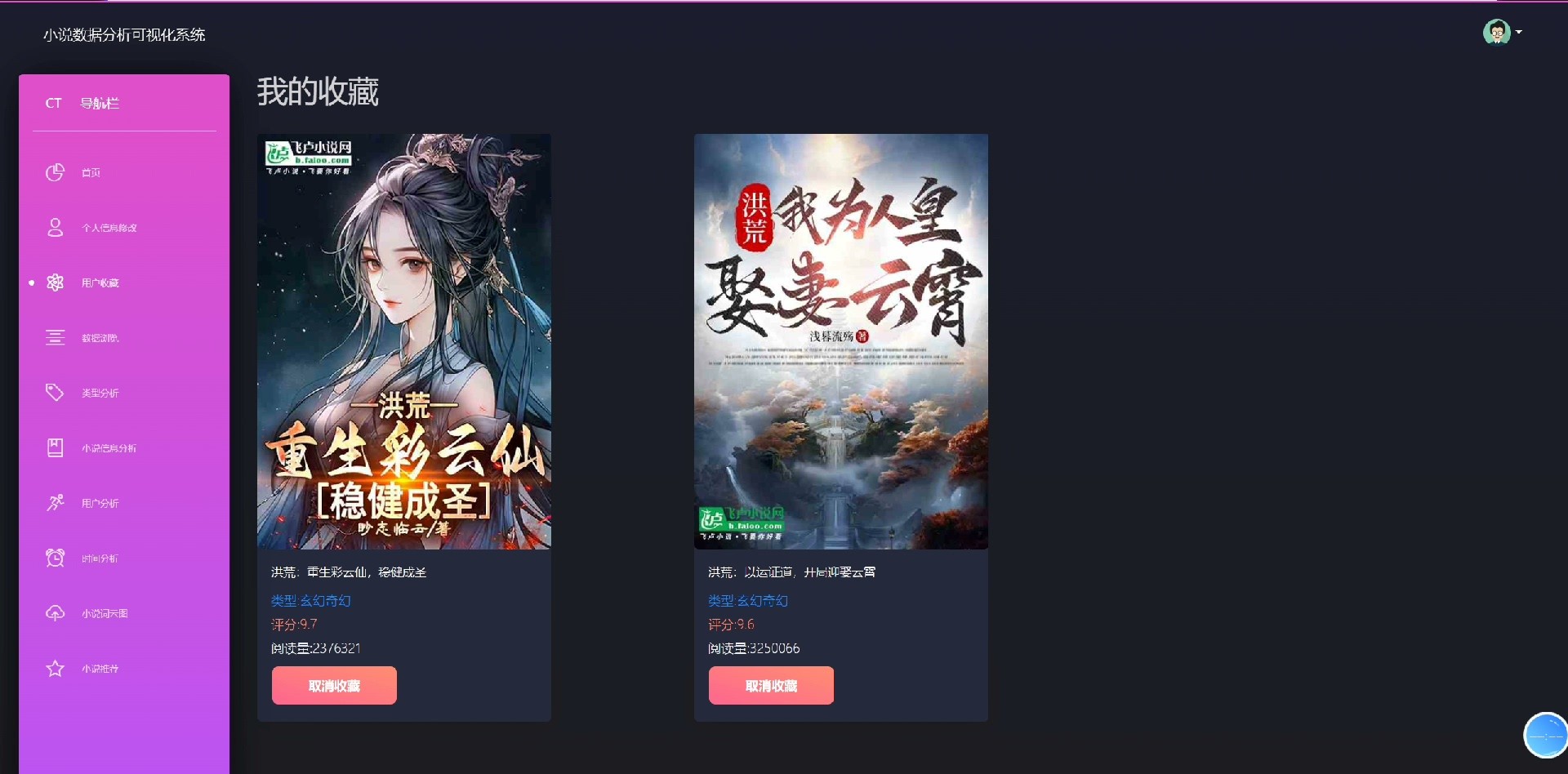
系统自带小说数据爬虫模块,可自动采集网络公开小说信息;同时配备Echarts图表展示热门小说排行、用户活跃趋势、推荐效果分析等关键指标,助力运营决策。
购买后提供完整源码、数据库脚本、开发文档及虚拟机分布式部署教程,确保开箱即用。
该项目不仅适合高校学生作为毕业设计或课程项目,也适用于开发者深入理解大数据推荐系统的工作流程。
无论是想掌握Spark应用、Hadoop集群搭建,还是研究推荐算法落地,这套系统都是不可多得的实战资源。
支持定制化部署服务,其他程序部署问题也可咨询。

发货方式
自动:在特色服务中标有自动发货的商品,拍下后,源码类 软件类 商品会在订单详情页显示来自卖家的商品下载链接,点卡类 商品会在订单详情直接显示卡号密码。
手动:未标有自动发货的的商品,付款后,商品卖家会收到平台的手机短信、邮件提醒,卖家会尽快为您发货,如卖家长时间未发货,买家也可通过订单上的QQ或电话主动联系卖家。
退款说明
1、源码类:商品详情(含标题)与实际源码不一致的(例:描述PHP实际为ASP、描述的功能实际缺少、功能不能正常使用等)!有演示站时,与实际源码不一致的(但描述中有"不保证完全一样、可能有少许偏差"类似显著公告的除外);
2、营销推广类:未达到卖家描述标准的;
3、点卡软件类:所售点卡软件无法使用的;
3、发货:手动发货商品,在卖家未发货前就申请了退款的;
4、服务:卖家不提供承诺的售后服务的;(双方提前有商定和描述中有显著声明的除外)
5、其他:如商品或服务有质量方面的硬性常规问题的。未符合详情及卖家承诺的。
注:符合上述任一情况的,均支持退款,但卖家予以积极解决问题则除外。交易中的商品,卖家无法修改描述!
注意事项
1、在付款前,双方在QQ上所商定的内容,也是纠纷评判依据(商定与商品描述冲突时,以商定为准);
2、源码商品,同时有网站演示与商品详情图片演示,且网站演示与商品详情图片演示不一致的,默认按商品详情图片演示作为纠纷评判依据(卖家有特别声明或有额外商定的除外);
3、点卡软件商品,默认按商品详情作为纠纷评判依据(特别声明或有商定除外);
4、营销推广商品,默认按商品详情作为纠纷评判依据(特别声明或有商定除外);
5、在有"正当退款原因和依据"的前提下,写有"一旦售出,概不支持退款"等类似的声明,视为无效声明;
6、虽然交易产生纠纷的几率很小,卖家也肯定会给买家最完善的服务!但请买卖双方尽量保留如聊天记录这样的重要信息,以防产生纠纷时便于送码网快速介入处理。
淘好品声明
1、作为第三方中介平台,依据双方交易合同(商品描述、交易前商定的内容)来保障交易的安全及买卖双方的权益;
2、平台上所有的资源都是亲测无误的,在平台下单安全有保障,有任何问题,可以随时联系在线客服。






