
商品详情






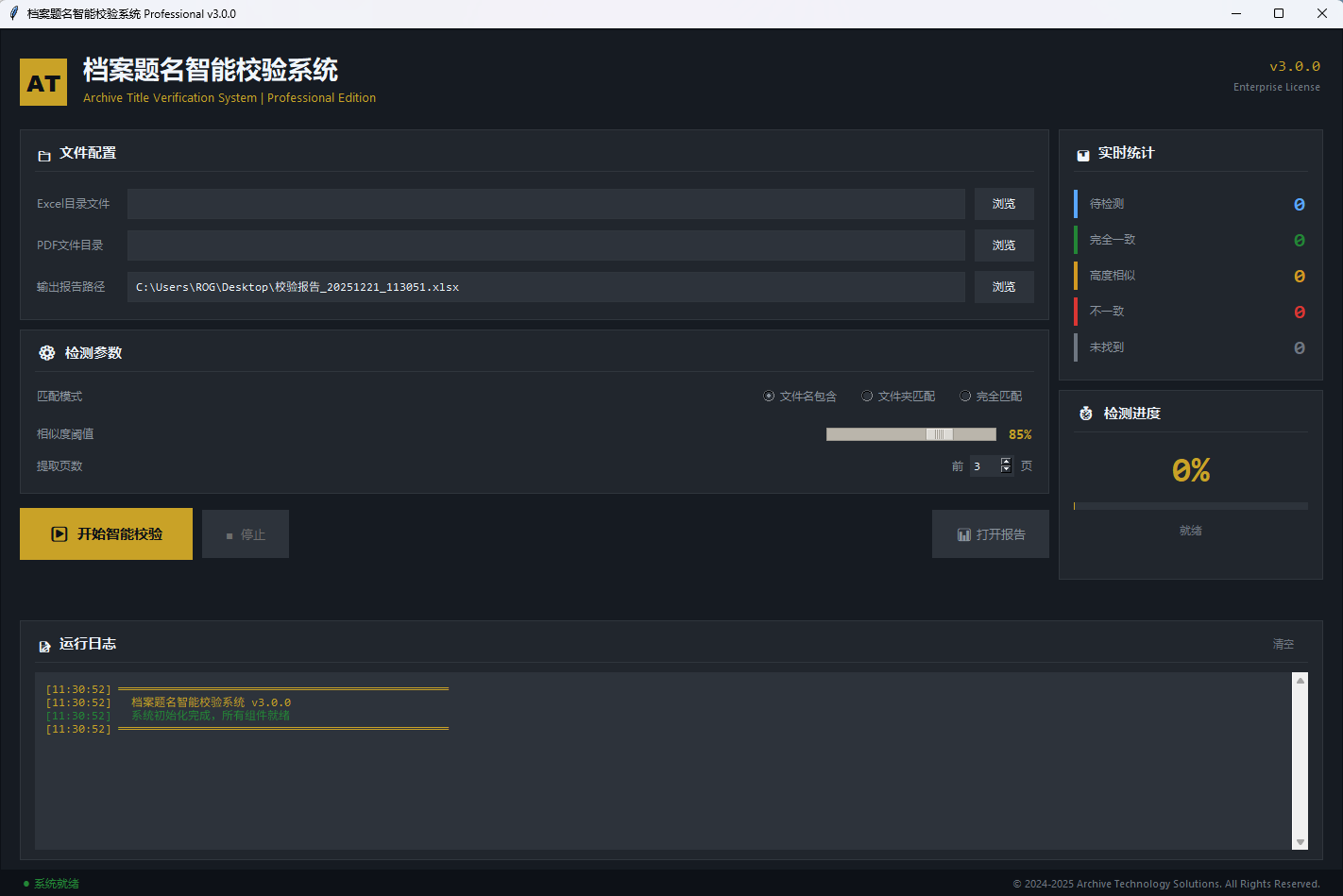
本系统是一款专为档案数字化管理开发的智能错别字检测工具,适用于各类图文档案的目录校对。
与传统依赖标准字库进行比对的方式不同,本系统通过分析图像中的实际文件标题内容,实现高精度的自动识别与错误预警。
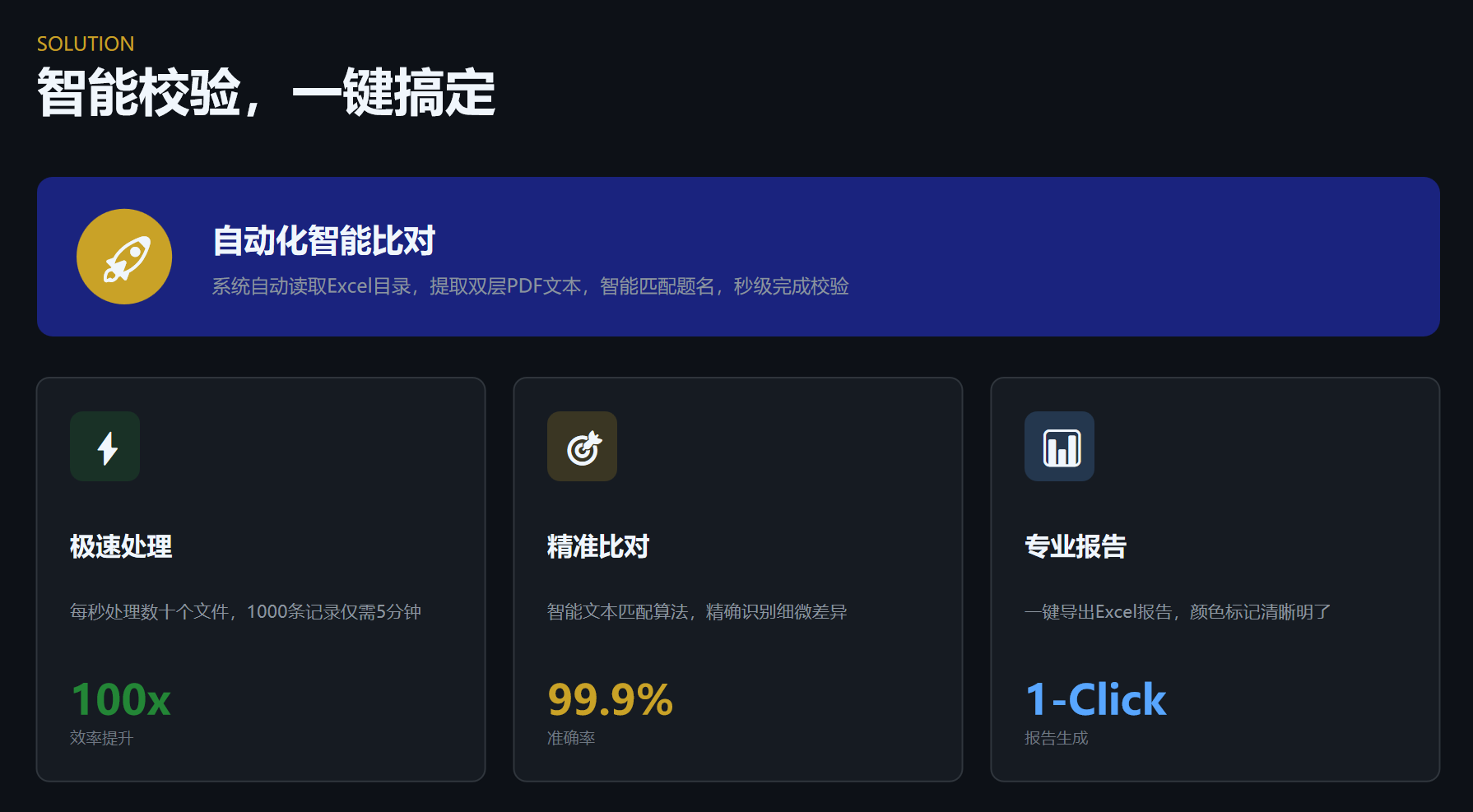
系统核心技术在于对扫描或拍摄后的图像文件中的标题文字进行提取与语义分析,通过与标准目录数据进行智能比对,快速发现错别字、漏字、多字等常见录入错误。
该方式不依赖于预设字库,而是结合上下文语境和常见命名规则,提升检测准确率。
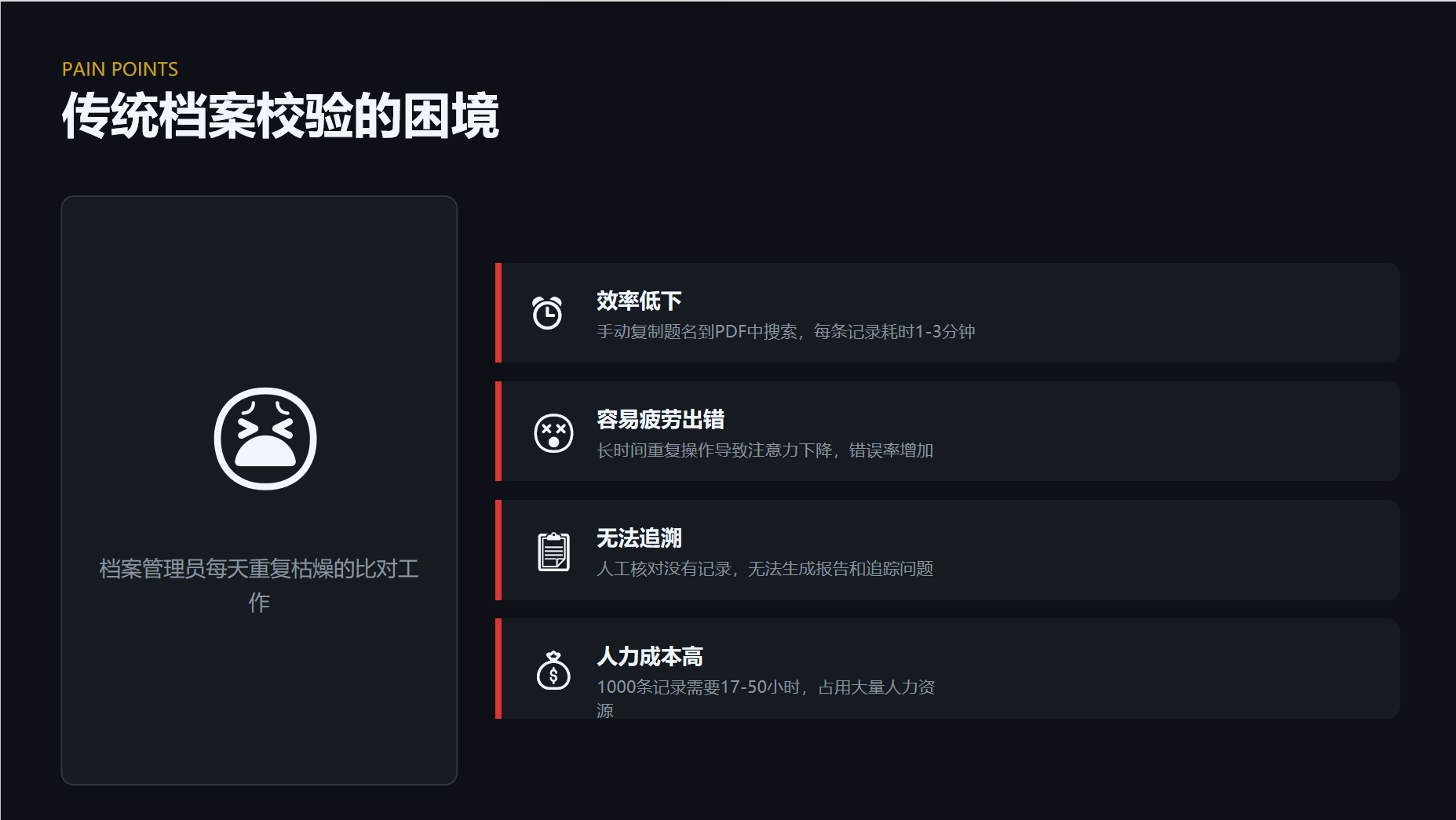
传统的错别字检测通常基于文本输入和固定词库匹配,难以应对图像中复杂字体、模糊文字或手写体等情况。
而本系统针对档案数字化过程中常见的图像资料特点优化算法,能够有效识别OCR识别后产生的语义偏差,提供更符合实际应用场景的纠错能力。
无论是政府机关、企事业单位还是图书馆、档案馆,在进行大量纸质档案电子化时,常因人工录入导致目录出错。
本系统可集成至数字化流程中,作为质量控制环节,显著降低后期维护成本,提高数据准确性与检索效率。
请注意,页面显示的标价仅为参考,并非最终成交价格。
由于系统功能定制化程度高,具体费用需根据使用规模、部署方式及技术支持需求综合评估。
欢迎在购买前与我们取得联系,获取详细方案与报价信息。




发货方式
自动:在特色服务中标有自动发货的商品,拍下后,源码类 软件类 商品会在订单详情页显示来自卖家的商品下载链接,点卡类 商品会在订单详情直接显示卡号密码。
手动:未标有自动发货的的商品,付款后,商品卖家会收到平台的手机短信、邮件提醒,卖家会尽快为您发货,如卖家长时间未发货,买家也可通过订单上的QQ或电话主动联系卖家。
退款说明
1、源码类:商品详情(含标题)与实际源码不一致的(例:描述PHP实际为ASP、描述的功能实际缺少、功能不能正常使用等)!有演示站时,与实际源码不一致的(但描述中有"不保证完全一样、可能有少许偏差"类似显著公告的除外);
2、营销推广类:未达到卖家描述标准的;
3、点卡软件类:所售点卡软件无法使用的;
3、发货:手动发货商品,在卖家未发货前就申请了退款的;
4、服务:卖家不提供承诺的售后服务的;(双方提前有商定和描述中有显著声明的除外)
5、其他:如商品或服务有质量方面的硬性常规问题的。未符合详情及卖家承诺的。
注:符合上述任一情况的,均支持退款,但卖家予以积极解决问题则除外。交易中的商品,卖家无法修改描述!
注意事项
1、在付款前,双方在QQ上所商定的内容,也是纠纷评判依据(商定与商品描述冲突时,以商定为准);
2、源码商品,同时有网站演示与商品详情图片演示,且网站演示与商品详情图片演示不一致的,默认按商品详情图片演示作为纠纷评判依据(卖家有特别声明或有额外商定的除外);
3、点卡软件商品,默认按商品详情作为纠纷评判依据(特别声明或有商定除外);
4、营销推广商品,默认按商品详情作为纠纷评判依据(特别声明或有商定除外);
5、在有"正当退款原因和依据"的前提下,写有"一旦售出,概不支持退款"等类似的声明,视为无效声明;
6、虽然交易产生纠纷的几率很小,卖家也肯定会给买家最完善的服务!但请买卖双方尽量保留如聊天记录这样的重要信息,以防产生纠纷时便于送码网快速介入处理。
淘好品声明
1、作为第三方中介平台,依据双方交易合同(商品描述、交易前商定的内容)来保障交易的安全及买卖双方的权益;
2、平台上所有的资源都是亲测无误的,在平台下单安全有保障,有任何问题,可以随时联系在线客服。






